
TL;DR
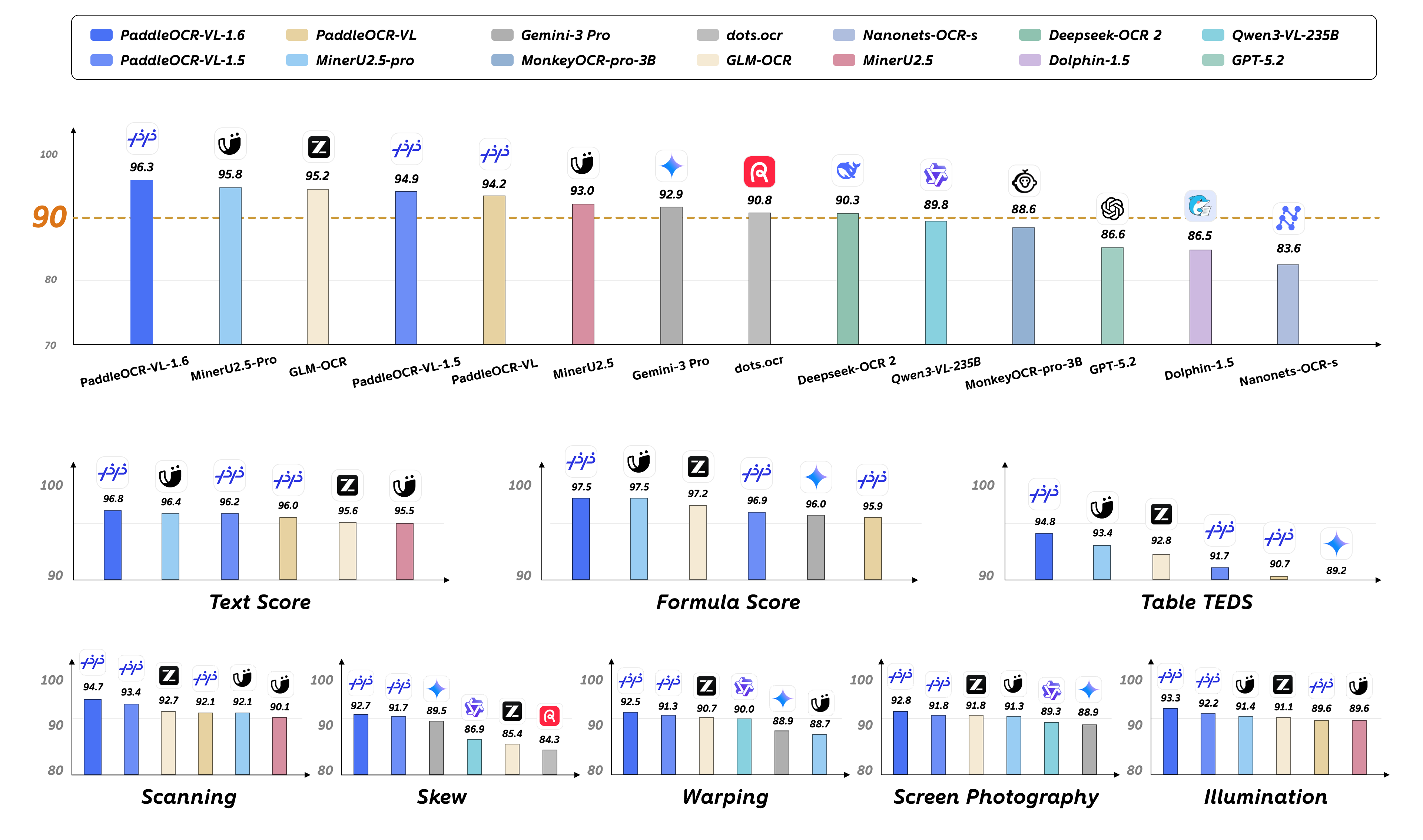
Baidu(百度)は、超軽量ドキュメント解析モデルの最新バージョン「PaddleOCR-VL-1.6」を発表した。本モデルはわずか0.9B(9億)パラメータでありながら、ベンチマーク「OmniDocBench v1.6」において96.33%という驚異的な精度で最高記録を更新。既存モデルの弱点を特定して強化する領域認識データ最適化フレームワークと段階的ポストトレーニング技術により、実用性を飛躍的に高めている。
Quick Facts
- モデルサイズ: 0.9B(9億パラメータ)
- 主要ベンチマーク: OmniDocBench v1.6にてSOTA(State-of-the-Art)となる96.33%を獲得
- 互換性: 前バージョン PaddleOCR-VL-1.5 と完全なアーキテクチャ互換性があり、シームレスな置換が可能
- 強化された要素: 複雑な表、中国古籍(古典文献)、難読・希少文字、印鑑・スタンプ検出、チャート解釈
オープンソースのOCR領域で世界的なシェアを誇るBaiduのPaddleOCRチームが、ドキュメント解析に特化したコンパクトビジョンランゲージモデル(VLM)「PaddleOCR-VL-1.6」をリリースした。本モデルは、巨大なVLMが独占していたドキュメント解析分野において、「超軽量かつ高精度」という新たな地平を開くものである。
PaddleOCR-VL-1.6の進化:データエンジンの仕組み
Baiduが導入した最大のエコシステム的アプローチは、「領域認識型データ最適化フレームワーク(Region-aware Data Optimization Framework)」である。このデータエンジンは、旧モデルの推論における「苦手な配置や構造の領域」を自動的に検出・抽出し、そのターゲット領域に対する局所的な画質やコンテキストの補強を行う。また、教師データの監修シグナルの信頼性を向上させ、高品質なアノテーションのみを再学習に供給する。
さらに、学習プロセスでは「段階的ポストトレーニング(Progressive Post-Training)」を採用。厳選されたデータセレクションと、強化学習(RL)を組み合わせることで、徐々に難易度の高いパターンを学習させ、ハルシネーション(誤認識)を最小限に抑え込んでいる。
[画像インプット] ──► [PaddleOCR-VL-1.6 (0.9B)] ──► [弱点領域の検出]
│ (領域認識フィードバック)
▼
[段階的ポストトレーニング (RL)] ◄── [強化データ収集] ◄── [データ補強エンジン]
性能ベンチマークと実用化の改善点
PaddleOCR-VL-1.6は、ドキュメント理解ベンチマークである「OmniDocBench v1.6」において、他社の巨大な独自クローズドソースモデルや10B超のオープンソースモデルを抑え、96.33%の最高得点を樹立した。「Real5-OmniDocBench」および「OmniDocBench v1.5」でも最高記録を塗り替えている。
特に実務上価値が高いのが、以下の改良点である。
- 表(Table)認識: 線が掠れている表や、セル内に複雑な文字が改行されて入っている表の構造化精度が飛躍的に向上。
- 印鑑(Seal/Stamp)検出: 契約書や公式文書に含まれる、文字の上に重ねて押された印鑑の正確な検出と文字分離。
- 中国古籍・希少文字: 古典籍に特有のレイアウト、縦書き文字、一般には使われない希少漢字の文字認識力が強化された。
日本企業への影響と日本から見た意味
日本のビジネスシーンにおいては、大量の紙の帳票、手書き申請書、法的な歴史ドキュメント(古文書や過去の契約書)のデジタル化が進められている。しかし、クラウド型の高額な巨大VLMを使い続けることは、コストやセキュリティ(機密データの送信)の観点からボトルネックとなっていた。
PaddleOCR-VL-1.6はわずか0.9Bという小型軽量設計であり、ローカルサーバーやコンシューマー向けのエッジデバイス、Dockerコンテナ内で低レイテンシで高速に実行できる。これにより、日本の自治体や地方金融機関におけるセキュアで高効率なOCR-DXイニシアティブの基盤として活用される可能性が極めて高い。
次に見る指標
- 日本語フォント・手書き文字の適応度: 日本語固有のレイアウト(縦横混在)や日本語手書き文字での精度テスト結果
- インフラのvLLM/Inference-Server統合状況: 公式提供されているvLLMコンテナイメージの性能と、秒間処理可能ドキュメント数(FPS)
- PaddlePaddle v3.2.1フレームワークとmacOS/Windowsへのローカルデプロイ環境の簡素化
よくある質問 (FAQ)
- Q: 1.5から1.6への移行にはコードの書き換えが必要ですか?
- A: いいえ。モデルアーキテクチャが1.5と完全な互換性を保っているため、読み込む重み(ウェイト)の指定を変更するだけの「ゼロコスト移行」が可能です。
- Q: どのような環境で推論を走らせるのが最適ですか?
- A: vLLMや公式のPaddleOCRサーバーを使用することで、NVIDIA AmpereやHopper等のGPUで高速動作させることができます。極めてコンパクトなため、省メモリGPUでもバッチ処理が実用的です。
- Q: 中国語以外のドキュメント、例えば英語や数式、プログラミングコードなども読み取れますか?
- A: はい。英語文書、LaTeX数式、テーブル、ソースコードが含まれる多次元レイアウトの構造化テキスト化(Markdown出力)に強みを持っています。