
中国の大規模言語モデル(LLM)開発のトップランナーである智譜AI(Zhipu AI / Z.ai)が、2026年6月13日に次世代フラグシップ大モデル『GLM-5.2』を発表し、2026年6月17日、そのモデルウェイトを最も自由度の高いMITライセンスのもとで全量オープンソース公開しました。
GLM-5.2は、単に長文を入力できるだけでなく、実用的なソフトウェア開発や自動調査といった**「長程タスク(Long-horizon tasks)」および「智能体工程(Agentic Engineering)」**を極限まで追求した、総パラメータ数7530億(753B)のMoE(Mixture of Experts:混合専門家)モデルです。
本記事では、フロントエンド開発評価システム『Code Arena』で実質世界トップに躍り出たその性能と、それを支える革新的なアーキテクチャの全貌に迫ります。
GLM-5.2 モデル基本スペック
| 項目 | 詳細 |
|---|---|
| 開発元 | 智譜AI (Zhipu AI / Z.ai) |
| モデルタイプ | MoE (Mixture of Experts) 混合専門家モデル |
| パラメータ数 | 総パラメータ 7,530億 (753B) / トークンあたり活性化パラメータ 約400億 (40B) |
| コンテキスト長 | 100万トークン (1M tokens) 無損失 |
| オープンソースライセンス | MITライセンス (無料商用利用可能) |
| 主な評価ランキング | ・Code Arena: 1595点 (実質世界1位 / オープンソース1位) ・Design Arena: 世界1位 ・FrontierSWE: オープンソース最高水準 |
| 主要技術特徴 | IndexShare, HiSparse, MTP, LayerSplit, KV8量子化 |
1. Code Arena実質世界一:驚異的なコーディング能力と長程タスク実行力
GLM-5.2の最大のハイライトは、クローズドソースを含む世界のトップモデルに匹敵、あるいはそれを凌駕する**「圧倒的なコーディング能力」**にあります。
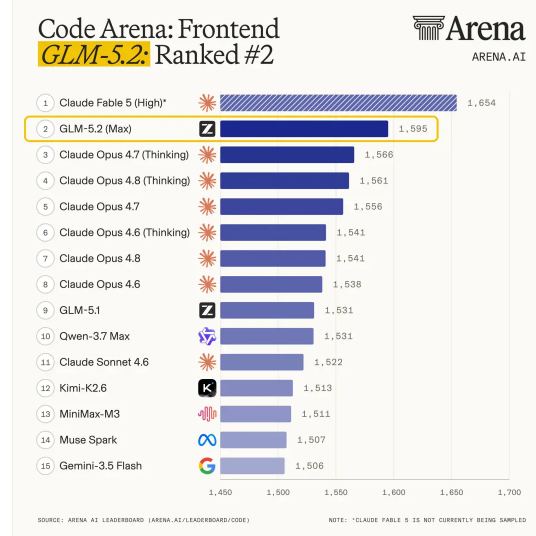
① Code Arenaで1595点、実質世界1位の座に
世界中の何百万人もの開発者が参加し、ブラインドテスト(モデル名を伏せた対抗評価)を行うフロントエンド開発の評価システム**『Code Arena』において、GLM-5.2は1595点を記録しました。 これは全体で第2位のスコアですが、首位の「Claude Fable 5」が現在正常に利用できない状態であるため、現在「実際に利用可能なモデル」の中では世界第1位、かつ「オープンソースモデル」の中ではダントツの1位**に君臨しています。
さらに、モデルの美意識やデザイン実装のセンスを競う**『Design Arena』**でも世界1位を獲得しており、実用的なコーディングだけでなく、優れたユーザーインターフェース(UI)を具現化する能力においても群を抜いています。
② 数日〜数ヶ月に及ぶ複雑なエンジニアリングを完遂
超長程・オープンエンドで難度の高いソフトウェアエンジニアリング能力を測るベンチマーク**『FrontierSWE』**において、GLM-5.2は「Claude Opus 4.8」に肉薄するスコアを叩き出し、オープンソースの限界を大きく押し広げました。
実際のストレステストでは、約88万文字の長文(ドキュメントや大規模なソースコード群)を一度に読み込み、満載状態のままWebサイト、モバイルアプリ、WeChatミニプログラムにまたがるフルスタックアプリケーションの構築・開発からデプロイまでを自律的に完遂する驚異的な実行力を見せました。
2. 1M無損失コンテキストを「低コスト・高効率」で動かす5つの技術革新
通常、100万トークン(1M)という極めて長いコンテキストを扱う場合、以下の2つの大きな壁にぶつかります。
- メモリ圧迫:履歴データを保持する「KVキャッシュ」が急増し、GPUのメモリ(VRAM)に収まりきらなくなる。
- 演算コストの爆発:コンテキスト長が伸びるにつれて計算量(FLOPs)が線形、あるいは二次関数的に増加し、推論速度が著しく低下する。
智譜AIは、GLM-5.2において以下の5つの技術革新を導入し、この課題を根本から解決しました。
① IndexShare(インデックス共有技術)
GLM-5.2はSparse Attention(疎なアテンション)を採用していますが、どのキー・クエリを活性化させるかを決定する「インデクサー」を、4つのアテンションレイヤーごとに共通化(共有)するIndexShareを導入しました。これにより、1Mコンテキストの超長文シナリオにおいて、トークンあたりの計算量(FLOPs)を**従来の最大2.9分の1(2.9×削減)**に抑えることに成功しました。
② HiSparse(階層型スパースメモリ管理)
アテンション計算時のKVキャッシュデータを階層化し、アクティブな(頻繁に使われる)データのみをGPUの高速メモリ(HBM)に置き、非アクティブな履歴データをホストメモリ(システムのメインRAM)に逃がすHiSparseシステムを構築。データ転送のオーバーヘッドを最小限に抑えつつ、GPUのメモリ不足(OOM)を劇的に回避します。
③ 改良型 MTP(複数トークン予測)レイヤー
推論を高速化する「投機的デコーディング(Speculative Decoding)」に用いられるMTPレイヤーを最適化しました。IndexShareと組み合わせることで、複数ステップの予測において最初のステップでのみインデクサーを計算し、以降は再利用するため、予測の採択長(Acceptance Length)が最大20%向上しました。
④ LayerSplit(レイヤースプリット)
KVキャッシュの展開をレイヤー単位で最適化するLayerSplit戦略により、リクエスト初期のプレフィル(Prefill)段階での瞬間的なメモリボトルネックを緩和し、スループット(処理能力)の大幅な向上を実現しました。
⑤ KV8 量子化
KVキャッシュのデータ精度をFP8またはINT8に量子化するKV8を採用。精度劣化を「実質無損失」に抑えながら、KVキャッシュのメモリフットプリントを半分に削減しました。
3. 「思考の深さ」を制御する Flexible Reasoning Mode
GLM-5.2は、ユーザーがタスクの難易度や計算コストに応じて、モデルの「推論の深さ」を調整できる**Thinking Effort(思考レベル)**設定(「High」および「Max」など)をサポートしています。
- シンプルなタスク(コード自動補完や部分的な修正など):思考レベルを抑えることで、高速かつ低コストなレスポンスを得られます。
- 複雑なタスク(プロジェクト全体の設計、複数ファイルにまたがるデバッグなど):レベルを「Max」に設定することで、モデルがユーザーに応答を返す前に自律的な検証や試行錯誤(CoT: Chain-of-Thought)を行い、より高品質でバグのない出力を得ることができます。
4. 国産算力(中国製半導体)への初日最適化とMITライセンスによるエコシステム拡大
智譜AIは、オープンソースエコシステムの健全な発展を強く意識し、初日から実用的なサポート体制を敷いています。
- 国産GPU・アクセラレータへの最適化: リリース初日より、**Huawei Ascend(華為昇騰)、T-Head(平頭哥)、Moore Threads(摩爾線程)、Biren(壁仞科技)、Cambricon(寒武紀)**といった中国国内の主要なAI半導体・算力プラットフォームとディープな最適化を完了。企業はインフラの選択肢を狭めることなく、スムーズに商用推論を運用できます。
- 最も寛容なMITライセンス: モデルの重み(Weights)はすべてMITライセンスのもとで公開されました。これにより、個人のホビー開発から、スタートアップや大企業の商用プロダクトへの組み込み、さらにはモデルのファインチューニングや再配布にいたるまで、ライセンス制限を心配することなく自由に利用できます。
- 簡単なアクセス:
完全なウェイトはすでにHugging Face(
zai-orgのオーガニゼーション下)および中国の**ModelScope(魔搭社区)**にアップロードされており、ローカルで動かすためのコードやAPI接続用のSDKも即座に利用可能です。
まとめ:オープンソースLLMが到達した新たな頂点
智譜AIの「GLM-5.2」の全量オープンソース化は、AIコーディング支援ツールの勢力図を大きく塗り替える可能性があります。これまで「高度な長程エンジニアリングタスク」はClaude 3.5 SonnetやGPT-4oなどのクローズドな有料APIの独壇場とされてきましたが、GLM-5.2の登場により、開発者は**「自前のサーバーでMITライセンスのOpus級エージェントを動かす」**という強力な選択肢を手に入れました。
1Mの無損失コンテキストと最適化されたMoEアーキテクチャが生み出す、次世代の「スマートエージェント体験」をぜひローカル環境やAPIで体感してみてください。